
L’Intelligenza Artificiale (IA) è il campo di ricerca che ha raggiunto un successo immenso negli ultimi anni e ha accelerato il nostro boom tecnologico e digitale. Tutti sappiamo quanto siano utili le raccomandazioni di pagine o video su Google e Youtube e quanto esattamente venga effettuata la ricerca di immagini o parole chiave. Sappiamo che i robot possono fungere da aiuto domestico o supportare i servizi aeroportuali. Ma sappiamo cosa sta succedendo nel retroscena della ricerca? Sappiamo come “pensa” l’IA? E soprattutto: conosciamo i suoi limiti?
Sommario
-
- Il concetto di “intelligenza artificiale”
- In che modo l’IA “impara”?
- L’intelligenza artificiale “impara” solo nella fase di sviluppo
- Miglioramento del riconoscimento vocale utilizzando l’IA
- Gli 8 limiti dell’intelligenza artificiale
- L’intelligenza artificiale non può “pensare” in modo astratto
- Problema di ricorsività
- Problema di trasparenza delle decisioni della macchina
- Limite di simulazione delle emozioni
- Le condizioni del quadro devono essere chiaramente definite
- Limiti morali ed etici
- Accesso ai dati e privacy
- E i robot assassini?
- Excursus: l’hype sul deep learning
- Prospettive: C’è il rischio di una perdita di posti di lavoro su larga scala?
Il concetto di “intelligenza artificiale”
Prima di tutto, l’Intelligenza Artificiale è un campo della scienza che abbraccia diverse aree specialistiche, come la psicologia, la linguistica e l’informatica, tra gli altri. Si dedica al compito di simulare e automatizzare comportamenti intelligenti, con l’obiettivo di sviluppare software in grado di risolvere problemi per cui è richiesta intelligenza. Descrive funzioni che sviluppano soluzioni complesse ai problemi e la loro fattibilità al fine di supportare o sostituire l’attività umana.
L’IA si divide in due livelli: l’IA simbolica e l’IA sub-simbolica. L’IA simbolica utilizza conoscenze date e porta a conoscenze e conclusioni logiche nella funzione di formulazioni “se-allora”. L’IA sub-simbolica utilizza conoscenze arbitrarie, l’ordine complesso delle quali è portato avanti dalle cosiddette “reti neurali artificiali”.
Le quattro categorie di intelligenza secondo Wahlster aiutano a capire come devono essere identificate le diverse competenze dell’IA. L’intelligenza cognitiva descrive l’apprendimento e l’interazione con la conoscenza. Qui la competenza della macchina è già una priorità. L’intelligenza sensorimotoria è l’intelligenza più ricercata nell’IA. È particolarmente riuscita nell’elaborazione di immagini, testi e audio e supera chiaramente l’abilità umana. L’intelligenza emotiva include i comportamenti empatici e le capacità di reazione che sono già stati implementati con successo nella robotica. C’è ancora un grande potenziale di miglioramento nell’implementazione della macchina. L’intelligenza sociale si esprime nell’interazione sociale e sembra essere la più difficile da controllare per l’IA. Come struttura sociale, gli esseri umani sono insuperabili.
Poiché l’IA è già più efficiente nel risolvere problemi in molte singole attività rispetto agli esseri umani, è attiva in tutti i settori della vita. Facilita e ottimizza la nostra vita quotidiana, perché è la tecnologia chiave per il collo di bottiglia della conoscenza umana. L’IA è principalmente utilizzata nei seguenti settori: mercato azionario e servizi finanziari (gestione dei dati), giochi (bot di gioco), medicina (analisi delle immagini e previsioni), automazione (sistemi di assistenza alla guida, guida autonoma) e sicurezza civile (audio e video: elaborazione e analisi). L’elaborazione del discorso e delle parole è particolarmente popolare nell’apprendimento automatico. I nuovi bot consentono l’automazione nelle traduzioni di testo o nei dialoghi (chatbot) così come nella produzione di musica e testi. L’intelligenza artificiale supporta quindi già molti settori di lavoro e sta diventando una forte concorrenza nell’economia competitiva.
In che modo l’IA “impara”?
Il Machine Learning (ML) è un ramo dell’IA. Si occupa del processo di apprendimento e quindi del processo di “pensiero” dell’Intelligenza Artificiale. Il Machine Learning descrive la competenza della macchina a ottenere conoscenza dai set di dati e a categorizzarne il contenuto. Il ML “impara” raccogliendo “esperienza” dal contenuto di set di dati esemplari, organizzando queste “esperienze”, sviluppando un modello complesso da esse e infine ottenendo “conoscenza” dai pattern e dalle leggi emerse. In altre parole, le macchine imparano essendo addestrate – nutrite con set di dati. Creano classificazioni automatiche da immagini, testi e dati sensoriali e sempre più spesso forniscono un’analisi più precisa e una previsione più veloce rispetto agli esseri umani. L’IA conosce il mondo esclusivamente dai dati.
Il Machine Learning è diventato un mezzo collaudato per il riconoscimento di pattern e lo sviluppo di processi, così come l’ottimizzazione degli strumenti nel business. Qui diventa chiaro perché i computer possono imparare molto più velocemente degli esseri umani: il fattore tempo determina il collo di bottiglia della conoscenza umana. Non hanno bisogno di pause o di sonno, non devono mangiare o morire. Possono funzionare 365 giorni all’anno, analizzare dati e imparare. Questo ridefinisce il termine apprendimento permanente.
Il Machine Learning è molto più efficace dell’apprendimento umano. Ad esempio, un software può svolgere più turni di gioco in un breve periodo di tempo di quante partite una persona potrebbe mai giocare prima della morte. I limiti umani di apprendimento, l’acquisizione di conoscenze, l’intelligenza, il processo di invecchiamento e infine la morte possono ora essere chiaramente superati dalle macchine. Dobbiamo ora temere che le macchine imparino e riflettano oltre i loro limiti, cioè come possiamo “pensare” noi esseri umani?
L’intelligenza artificiale “impara” solo nella fase di sviluppo?
La risposta è: no. Di solito, i computer possono fare solo ciò che viene esplicitamente detto loro di fare. La programmazione – gli algoritmi, cioè le istruzioni nel codice del programma – determina cosa l’IA deve imparare. Esistono tre strategie per come l’IA può imparare: apprendimento supervisionato, non supervisionato e per rinforzo.
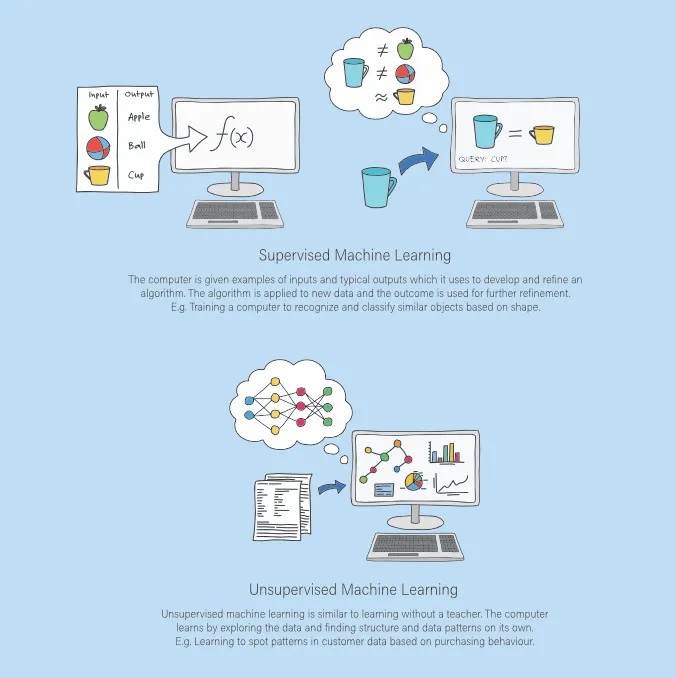 Un’infografica che mostra l’apprendimento supervisionato e non supervisionato.
Un’infografica che mostra l’apprendimento supervisionato e non supervisionato.
Nell’apprendimento supervisionato, è sempre strettamente specificato quale input e output possono essere attesi. Il risultato dell’apprendimento è fisso e può essere “monitorato” dagli esseri umani durante l’addestramento. L’apprendimento non supervisionato è addestrato senza valori target precedentemente definiti, cioè senza “supervisione” umana. Di conseguenza, l’IA impara diverse funzioni di cluster o segmentazione, ad esempio, e quindi apre nuove conoscenze sulla distribuzione dei dati. L’apprendimento per rinforzo descrive l’approccio dinamico dell’IA per imparare forme di strategia che ottengono una ricompensa al fine di determinare il massimo potenziale strategico, ad esempio nei videogiochi.
Pertanto, nella fase di sviluppo è chiaramente definito fin dall’inizio cosa ci si aspetta dall’IA, come dovrebbe “imparare” e come possono apparire i risultati. L’IA segue rigorosamente le istruzioni del suo codice di programma, viene “addestrata” con tonnellate di set di dati e alla fine soddisfa lo scopo o no. Se, ad esempio, viene dato un risultato diverso durante l’apprendimento supervisionato, il gruppo di ricerca migliora o riformula l’algoritmo. Non appena l’IA restituisce l’applicazione ripetutamente senza errori, cioè ha “imparato” con successo, è pronta per essere trasferita sul mercato commerciale. Tuttavia, bisogna fare attenzione a non enfatizzare troppo l’ottimizzazione dei dati di addestramento, per evitare un “overfitting”. Questo descrive la perfezione dell’apprendimento dei dati di addestramento, che nell’applicazione pratica non corrisponde ai dati reali. Questo può anche rendere inutilizzabile l’IA sviluppata.
Qui diventa evidente che il processo di apprendimento dell’IA avviene solo nella fase di sviluppo. Viene poi introdotto sul mercato come programma finito e da quel momento esegue sempre l’algoritmo specificato. “L’apprendimento” non è né pianificato né avviene successivamente.
Le competenze ML che attualmente vengono utilizzate in economia sono in particolare: formazione di gruppi, classificazione di oggetti, stima del valore e previsione, selezione di azioni per agenti, riconoscimento di immagini, riconoscimento vocale, estrazione di testi, elaborazione di informazioni, comprensione del testo.
Miglioramento del riconoscimento vocale utilizzando l’IA
Un progresso significativo nell’IA risiede nel riconoscimento vocale. Invece del solito input e output utilizzando la tastiera, da un po’ di tempo le istruzioni vengono date tramite il linguaggio in molti dispositivi, ad esempio gli smartphone o le applicazioni per la smart home. L’IA può facilmente apprendere il vocabolario e le basi della grammatica. Anche il contenuto semantico è difficilmente un problema, dato che per “l’apprendimento” è disponibile un volume di dati quasi infinito.
Gli 8 limiti dell’intelligenza artificiale
L’idea che il software possa apprendere dai dati e modificare i propri algoritmi per sfruttare ancora di più il suo potenziale a lungo termine è fondamentale nell’apprendimento automatico. Tuttavia, l’apprendimento automatico non ha solo un accesso infinito ai database, ma anche grandi restrizioni e limiti decisivi che difficilmente possono essere superati, come mostrano i seguenti 8 punti.
1. L’intelligenza artificiale non può “pensare” in modo astratto
L’intelligenza artificiale non è in grado di reagire in modo flessibile a piccoli cambiamenti o a nuovi problemi di applicazione. Non può riconoscere e stabilire alcun collegamento logico o casuale in concetti astratti. Non può trasferire le conoscenze che ha appreso ad altri livelli. Ad esempio, se le immagini nel set di dati hanno pochi pixel, l’IA fa fatica a classificare correttamente queste immagini. Semplicemente non le riconosce. Questo è un grande problema, specialmente con la guida autonoma. I segnali stradali sui quali sono stati applicati adesivi o graffiti non sono più riconoscibili per l’IA del programma di assistenza alla guida. Questo ha conseguenze fatali e porta a notevoli difetti di qualità e sicurezza. Ci sono già tentativi di incorporare intenzionalmente possibili errori nel set di dati al fine di aumentare la capacità di apprendimento. Tuttavia, questo approccio non ha ancora avuto successo.
Questa incapacità di adattarsi a circostanze cambiate è dovuta al fatto che l’IA “impara” solo ciò che è disposto nella programmazione. Tuttavia, la codifica può fornire conclusioni astratte solo in misura limitata, in modo che la flessibilità del “pensiero” logico non possa essere realizzata. Per questo motivo, ad esempio, il riconoscimento di modelli è la loro migliore abilità, che gli esseri umani non potrebbero mai acquisire nella quantità di set di dati e, soprattutto, nel breve lasso di tempo.
Il funzionamento del cervello umano è estremamente complesso, tanto che può derivare tratti logici e concetti astratti senza dover apprendere ogni problema da zero. Ma l’IA non può mettere in discussione le conclusioni o pensare in modo critico alle cose. Ad un certo punto non considererà che il riconoscimento di modelli monotono non è più una sfida per lei. Che vorrebbe avere qualcosa di impegnativo e iniziare a utilizzare le sue competenze altrove. Questo modo di pensare non è possibile da “replicare” con algoritmi, perché l’IA non ha una “coscienza”, non ha una sensazione di dolore o un sentimento che cresce al di là di se stessa. La simulazione della “coscienza” umana non è possibile se non è nemmeno chiaro in che misura la coscienza umana può essere afferrata organicamente.
2. Problema di ricorsività
Di conseguenza, le macchine possono apprendere e diventare “più intelligenti”, ma non hanno la capacità di creare da sole una macchina ancora più potente. Non esiste un’IA che possa migliorare se stessa. Solo gli esseri umani possono utilizzare le loro abilità cognitive e l’intelligenza creativa e associativa per concepire e costruire macchine ottimizzate. Di conseguenza, l’apprendimento automatico è limitato solo all’aumento della competenza e della velocità di apprendimento.
É importante sottolineare che questo rappresenta un limite significativo nell’attuale stato dell’IA. Nonostante la potenza computazionale e l’abilità di elaborare enormi quantità di dati, l’IA non possiede ancora l’autocoscienza o la capacità di auto-migliorarsi senza l’intervento umano. Ciò sottolinea l’importanza del ruolo umano nello sviluppo e nell’ottimizzazione continua dell’intelligenza artificiale. L’IA, per quanto avanzata, rimane uno strumento che dipende dalle capacità umane per la sua evoluzione e per superare le proprie limitazioni.
3. Problema di trasparenza delle decisioni della macchina
C’è un grande deficit nella tracciabilità del processo decisionale dell’IA. Come l’IA decide e perché non può essere illustrato, in quanto essa raffigura e seleziona diversi filoni all’interno del processo di apprendimento fino a giungere a un risultato. Questa selezione non può essere visualizzata in nessun momento, complicando così la trasparenza continua che è indispensabile nelle attività competitive. Si sta già lavorando per scomporre il processo di apprendimento dell’IA in singoli strumenti IA. Tuttavia, ci vorrà del tempo per raggiungere una svolta in questo senso.
É importante capire che la mancanza di trasparenza nelle decisioni prese dall’IA rappresenta un problema significativo, noto come “scatola nera” dell’IA. Questo implica che le decisioni prese da un sistema di intelligenza artificiale possono essere complesse e non facilmente comprensibili per gli umani. Inoltre, questa mancanza di trasparenza può portare a problemi etici e di responsabilità, specialmente quando l’IA viene utilizzata in settori critici come la medicina o la sicurezza. Pertanto, è fondamentale lavorare verso l’obiettivo di rendere i sistemi di IA più comprensibili e trasparenti, per garantire la loro accettazione e fiducia da parte della società.
4. Limite di simulazione delle emozioni
L’IA può imparare a “comprendere” la semantica delle parole e delle frasi e rispondere in modo appropriato. Ad esempio, i chatbot utilizzati nel servizio clienti possono “comunicare” in modo adeguato e rispondere automaticamente a domande semplici. Tuttavia, quando si parla con l’IA di un robot, si nota rapidamente quanto sia limitata la capacità di comunicazione. Infatti, la percezione di una persona non si limita a un gioco di domande e risposte. Qui, espressioni facciali, gesti, azioni istintive o espressioni empatiche di sentimento vengono utilizzate per “trasmettere” un’impressione complessiva che non può essere pienamente percepita da una macchina, figuriamoci simulata in modo uguale. Per fare ciò, sarebbero necessari diversi sensori che analizzano e collegano contemporaneamente il comportamento e determinano una risposta di output appropriata. Una macchina non può implementare questa cosiddetta “fusione di sensori”. La funzione di collegamento cognitivo è disponibile solo nel cervello umano.
5. Le condizioni del quadro devono essere chiaramente definite
L’intelligenza artificiale risulterebbe quindi l’effetto di numerosi processi interconnessi che scambiano valori tra loro, cosa che non è fattibile in questo modo. Di conseguenza, non ci sarà un’intelligenza macchinale superiore. E forse è meglio così. Perché i limiti e le condizioni del quadro sono necessari per fini commerciali. I problemi, i risultati e le soluzioni proposte devono essere chiaramente definiti e formulati per ottenere il risultato desiderato. L’IA, quindi, è utilizzata per raggiungere specifici obiettivi competitivi. Deve scomporre insiemi di dati in modo tale da offrire un valore aggiunto all’azienda. La fiducia in un prodotto deve essere garantita attraverso l’affidabilità e una qualità costante. Deviazioni nei risultati dell’IA significherebbero una mancanza del prodotto e dell’obiettivo. Tali problemi di applicazione sono inutili per fini commerciali.
Inoltre, è importante sottolineare che l’IA deve operare entro certi limiti etici e di sicurezza. Ad esempio, l’IA dovrebbe essere progettata e utilizzata in modo responsabile per garantire il rispetto della privacy e della sicurezza delle informazioni. Inoltre, l’IA dovrebbe essere utilizzata in modo da minimizzare l’impatto negativo sulla società e sull’ambiente. Infine, mentre l’IA può automatizzare molti compiti, ci saranno sempre aspetti del lavoro e della creatività umana che non possono essere replicati o sostituiti dalle macchine.
6. Limiti morali ed etici
L’intelligenza artificiale ha un enorme problema di discriminazione. Non riesce a catturare contenuti di immagini o testi ambigui da record di dati. Le ambiguità sorgono principalmente attraverso una connessione cognitiva con i valori provenienti da contesti letterari, religiosi, matematici, sportivi o anche facciali e linguistici. L’IA selezionerebbe solo un singolo elemento di informazione rilevante da tali insiemi di dati, ma non può valutare più contenuti e pensare in modo associativo, come facciamo noi umani. Questo comporta un’elevata probabilità di errore, che è moralmente o eticamente non rappresentativa. Ad esempio, l’IA ha difficoltà a riconoscere idiomi o formulazioni discriminatorie. Le conoscenze specifiche per età, genere o religione così come etiche non possono semplicemente essere codificate e rese “riconoscibili” in insiemi di dati. Apprendiamo queste informazioni in modo associativo e situazionale nel corso della nostra vita. Questa capacità cognitiva è socialmente fondamentale. L’IA non può fare questo. Non sa cosa sia un insulto. Se, ad esempio, l’IA in bot sociali o di gioco riproduce informazioni che sono discriminatorie e denigratorie, ne derivano rischi imprenditoriali e gravi problemi di immagine. La difficoltà: l’IA non sa fare di meglio perché non può capirlo.
Vorrei sottolineare che l’IA, come qualsiasi altro strumento tecnologico, non è intrinsecamente buona o cattiva, ma è il suo uso che può portare a risultati positivi o negativi. Questo mette in evidenza l’importanza di un’etica dell’IA solida e ben considerata, che tenga conto non solo della precisione e dell’efficienza, ma anche dei valori umani fondamentali come l’equità, la privacy e la dignità. È necessario un maggiore impegno per garantire che l’IA sia progettata e utilizzata in modo da rispettare questi principi, e per rispondere in modo efficace quando si verificano violazioni.
7. Accesso ai dati e privacy
Un problema altrettanto grande nell’IA riguarda l’accesso ai dati e la privacy. L’IA è digitale e virtuale, ascolta e legge sempre tutto. L’IA è integrata negli altoparlanti e nelle telecamere di tutti i dispositivi come un mini spia virtuale. I segnali degli smartphone sono pronti per essere ricevuti 24 ore su 24. Sappiamo, ben prima di Edward Snowden, che mettiamo a rischio la nostra privacy. Come possiamo proteggerci da questo? Coprendo sempre le telecamere di laptop, tablet e smartphone? Disattivando i microfoni di tutti i dispositivi mobili? Bloccando i segnali utilizzando la modalità aereo o mettendo lo smartphone nel frigo? L’IA può utilizzare ed elaborare qualsiasi accesso ai dati. Tutte le informazioni vengono salvate e analizzate in breve tempo. Ma l’IA può anche proteggere la privacy in cambio. Se si prescrivono e implementano adeguate funzioni di protezione dei dati con la possibilità di cancellazione immediata dopo l’utilizzo dei dati, senza che ciò possa essere eluso, speriamo che in futuro lo standard sarà un sistema anonimo e meno tracciabile.
É importante notare che, nonostante le preoccupazioni legittime sulla privacy, l’IA ha anche il potenziale di contribuire in modo significativo alla protezione dei dati personali. Può aiutare a identificare e prevenire violazioni della privacy, come furti di identità o violazioni dei dati, e può svolgere un ruolo chiave nel garantire che le informazioni personali siano gestite e utilizzate in modo appropriato e sicuro. Tuttavia, per realizzare questo potenziale, è fondamentale che i sistemi di IA siano progettati e regolamentati in modo tale da rispettare i diritti alla privacy degli individui. La responsabilità di assicurare ciò spetta sia agli sviluppatori di IA che alle autorità di regolamentazione.
8. E i robot assassini?
Che senso ha l’anonimato e la protezione dei dati quando macchine killer autonome sono già in uso? Le armi autonome di distruzione di massa non sono più un’utopia. Esistono già. Il robot completamente automatico ma stazionario di Samsung, ad esempio, può perlustrare un’area enorme e identificare ogni persona da 4 km di distanza, avvertirla prima di entrare nell’area e infine ucciderla. I droni volanti autonomi che (ancora) rispondono alle istruzioni di un soldato umano nel bunker di controllo hanno il loro punto debole nella sequenza radio. I segnali potrebbero essere facilmente interrotti da qualsiasi luogo e possono diventare un facile bersaglio per gli aggressori. Dove porta questa leggerezza?
Ciò richiede linee guida etiche globali che affermino che i robot non devono ferire le persone. Si ritiene che non sia l’IA intelligente a causare paura, ma l’IA stupida che prende decisioni incompetenti. Ma non dovresti avere paura delle macchine, ma delle persone e della loro intenzione dietro di esse. L’IA prende decisioni sbagliate solo se è stata programmata in anticipo per tale risultato. Pertanto, deve esserci una base etica per l’uso dell’IA al fine di prevenire abusi.
L’uso di armi autonome solleva una serie di questioni etiche e morali. Al centro di questi dibattiti c’è la questione della responsabilità: chi è responsabile se un’arma autonoma causa danni non intenzionali o illegali? Inoltre, c’è la preoccupazione che l’uso di tali armi possa rendere la guerra più probabile o più distruttiva, dato che riduce il rischio per i soldati umani. Per questo motivo, molti esperti e organizzazioni hanno chiesto un divieto internazionale sull’uso di armi autonome. Infine, è fondamentale che qualsiasi utilizzo dell’IA nel contesto militare rispetti il diritto internazionale umanitario, che richiede che gli attacchi siano proporzionali, discriminanti e necessari.
Excursus: l’hype sul deep learning
Un ramo particolare del Machine Learning è il cosiddetto modello di apprendimento profondo (Deep Learning, DL). Un concetto di apprendimento basato su strutture più dettagliate utilizzando reti neurali. Questi neuroni generati artificialmente dovrebbero contribuire a rendere ancora più trasparenti i risultati derivati da milioni di esempi di addestramento – provenienti da un enorme set di dati. Il nome del modello DL si basa sul sistema nervoso biologico del cervello umano. Il Deep Learning simula il “pensiero” umano usando reti neurali artificiali in modo tale che la valutazione del contenuto dei dati attraverso molteplici connessioni porti a un processo di esclusione. Similmente alla “legge del tutto o niente” umana, l’IA decide qui se le informazioni devono essere trasmesse e quindi compresse o meno. Il vantaggio: attraverso i cosiddetti “grafi di conoscenza”, le decisioni della macchina possono essere rese più trasparenti. Il problema, tuttavia, è che questo concetto si basa su infiniti esempi di addestramento, ovvero ha una fame insaziabile di dati per avere successo. Di conseguenza, risulta enormemente dipendente dal set di dati originale in seguito. Ciò la rende incline a calcoli errati quando non sono disponibili dati sufficienti.
Il Deep Learning sta già ottenendo successo nel trattamento del linguaggio, nel riconoscimento di pattern, nel riconoscimento di oggetti e nella bioinformatica. Il Deep Learning viene principalmente utilizzato in AlphaGo e nel software open source. Il Deep Learning consente di elaborare enormi volumi di dati in tempo reale, aspetto particolarmente importante in finanza, quando lo stoccaggio di tali set di dati giganteschi non può essere realizzato.
Ampliando il concetto, il Deep Learning sta rivoluzionando settori come la diagnostica medica, la visione artificiale e il riconoscimento vocale, offrendo strumenti in grado di analizzare e interpretare complessi pattern di dati con una precisione senza precedenti. Nonostante i suoi successi, il deep learning ha anche i suoi limiti, tra cui la sua dipendenza da grandi quantità di dati etichettati e la sua opacità intrinseca, che rende difficile capire perché ha preso una certa decisione. Questi problemi rappresentano una sfida significativa per gli sviluppatori di IA, ma anche un’opportunità per sviluppare nuovi metodi e tecniche che possono superare questi ostacoli.
“Se i dati sono il nuovo petrolio, il Machine Learning è la raffineria che raffina quei grandi set di dati.”
— Toby Walsh, autore e professore di IA
Prospettive: C’è il rischio di una perdita di posti di lavoro su larga scala?
Di fronte all’uso di successo in tutti i campi della vita e ai benefici straordinari dell’intelligenza artificiale, molte persone guardano all’IA con scetticismo quando si tratta dei loro lavori. Si potrebbe temere che l’IA supererà i punti di forza unici dell’essere umano e supererà le loro competenze?
È poco probabile. I limiti del Machine Learning mostrano chiaramente che la maggior parte delle possibilità tecnologiche consiste nel sostituire i processi di lavoro che sono per lo più monotoni, che elaborano una grande quantità di dati e che possono essere automatizzati. Questo significa che l’intelligenza artificiale non può sviluppare un'”intelligenza superiore”, ma mira solo alla velocità e all’accuratezza.
Il valore del lavoro non si perde, ma si sposta sempre o addirittura crea nuove opportunità. Il passato mostra che il modo di lavorare doveva essere reinventato ogni volta che il progresso tecnologico lo migliorava o addirittura lo posticipava. Sono stati creati nuovi tipi di luoghi di lavoro, con sfide sconosciute e nuovi approcci creativi e innovativi.
L’uso di un collegamento tra l’IA e la competenza umana può già essere visto sotto il termine di “empowerment intelligente”. Molte aziende attribuiscono grande importanza ai vantaggi della combinazione delle capacità di pensiero umano con le applicazioni dell’intelligenza artificiale. C’è un grande potenziale di innovazione se riusciamo a utilizzare l’IA per organizzare il nostro orario di lavoro in modo tale che l’IA si occupi del lavoro basato sui dati e il resto del tempo possa essere investito in modo significativo in progetti creativi. Forse questo approccio ci permetterà persino di ridurre l’orario di lavoro settimanale e di darci più tempo per le attività ricreative in futuro? Il futuro lo dirà.